
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |
- 디자인패턴
- 정렬 알고리즘
- 자료구조
- 생성패턴
- 외적
- Unreal Collision
- Factory method pattern
- 유니온-파인드
- BFS
- 두 직선사이 교점
- Set
- Trie
- 관찰자(Observer) 패턴
- object channel
- 분포 기반 정렬 알고리즘
- 트리순회
- 깊이 우선 탐색
- Union-Find
- 트리
- 동적 계획법
- 비교 기반 정렬 알고리즘
- 경량 패턴
- Abstract Factory pattern
- 명령패턴
- command pattern
- 스택
- Queue
- 팩토리패턴
- flyweight pattern
- C++ STL 정리
- Today
- Total
KimMK
탐색 알고리즘 본문
- 내부 탐색: 주기억 장치에 모두 적재 후 탐색
- 순차
- 이진
- 이진 트리
- 해싱
- 외부 탐색
- 균형 트리
순차 탐색

첫 번째 레코드부터 시작해서 마지막 레코드까지 차례로 탐색 키를 비교하는 알고리즘
비교 횟수는 성공적이지 않은 탐색에 대해 N + 1회 비교, 성공적인 탐색에는 평균적으로 N/2회 비교
정렬된 연결 리스트로 구현된 순차 탐색은 항상 평균적으로 N/2회 비교
이진 탐색

성공적인 탐색과 그렇지 않은 탐색 모두 logN + 1회 이상의 비교를 하지 않음
리스트가 정렬되어 있어야 하므로 정렬된 상태를 유지하는데 추가적인 비용을 소비함
이진 트리 탐색

작은 키를 가지고 있는 레코드는 왼쪽 부분트리, 같거나 큰 키를 가진 레코드는 오른쪽 부분트리
과정: 루트와 키를 비교하고 키가 루트보다 작다면 왼쪽 서브 트리로 이동, 크다면 오른쪽 서브 트리로 이동… 트리를 중위 순회하면 데이터를 정렬하는 효과를 봄
최악의 경우 N개의 키를 가진 트리를 탐색하는데 N번의 비교 필요
해싱
모든 키의 레코드를 산술 연산에 의해 한 번에 바로 접근할 수 있는 기법
단계
- 해시 함수를 통해 탐색 키를 해시 테이블 주소로 변환
- 같은 테이블 주소로 매핑되었을 경우 충돌을 해결해야 함
- 메모리의 제한이 없을 경우: 키를 메모리 주소로 사용하면 어떤 탐색이든지 한 번의 메모리 접근으로 수행 가능
- 시간에 제한이 없을 경우: 최소한의 메모리를 사용해 데이터를 저장하고 순차 탐색
두 극단 사이에서 합리적인 균형을 제공하는 것이 해싱
사용 목적: 가용한 메모리를 효과적으로 사용하면서 빠르게 메모리 접근
해시 함수는 키 값을 테이블 주소로 변환하는 함수
- 나눗셈법: h(k) = k mod m (m값의 선택은 2의 거듭제곱과 상당한 차이가 있는 소수를 선택하는 것이 좋음)
- 곱셈법: 소수가 아닌 m을 선택해야 하는 경우 사용, m의 값은 중요하지 않음, m = 2^p로 선택
연쇄법 = 동일 주소로 해시되는 모든 원소가 연결 리스트 형태로 연결 (대표적인 오픈 해싱 기법), 폐쇄 주소법
- 장: 삭제가 용이
- 단: 포인터 저장을 위한 기억공간이 필요, 기억 장소 할당이 동적

선형 탐사법 = h(k) = k mod m, 개방 주소법 사용(m값이 입력 원소의 수보다 커야 함)
※ 개방 주소법: 충돌을 내부에서 처리
- 단: 클러스터링이 발생 → 점유된 위치가 연속적으로 나타나는 뭉치가 있으면 점점 커지는 현상, 탐색 시간을 증가시킴


- 충돌이 발생했을 때 해결 방법
- 폐쇄 주소법 = 링크드 리스트를 하나 추가함
- 개방 주소법 = 해쉬 테이블 안에서 충돌을 해결함
이중 해싱
클러스터링 문제를 해결한 해싱
▶ 선형 탐사법은 두 번째 이후에 탐색 위치는 초기 탐색 위치에 따라 결정함, 두 번째 이후 탐색 위치가 처음 탐색 위치와 무관하다면 클러스터링을 제거할 수 있음


특성
- 평균적으로 선형 탐사보다 적은 탐색 회수를 가짐
- 선형 탐사에 비해 작은 테이블 크기를 가지고 동일한 탐색 성능
- 대량 데이터 검색이 뛰어남
- 어떤 값이 있으면 알고리즘으로 변환시켜 나온 결과 값이 해시 값 → 해시 값은 원래 값으로 돌아올 수 없음(암호화와 관련)
※ 이진 트리보다 해싱을 사용하는 이유 = 간단, 상대적으로 빠른 탐색 시간
※※ 이진 트리의 장점
- 동적(삽입 횟수를 몰라도 됨)
- 최악의 경우 성능 보장 (해싱의 경우 모든 값을 같은 장소로 해싱하는 경우가 발생할 수 있음)
- 사용할 수 있는 연산의 종류가 많음
균형 트리(Balanced Tree)
이진 트리의 경우 최악의 경우(정렬되거나, 역순으로 정렬되거나, 큰 키와 작은 키가 교대로 나오는 방식으로 정렬돼 있는 경우) 성능이 나쁨.
종류: 2-3-4 트리, 레드블랙(RB)트리, AVL트리 → 이진 균형 트리
※ MST(다원 탐색 트리) 종류 = B, B+, B* 트리, Trie(트라이)
2-3-4 트리
이진 탐색 트리에서 발생하는 최악의 상황을 방지하기 위해 규칙을 추가함
규칙
- 트리에 있는 하나의 노드가 하나 이상의 키를 가질 수 있음
- 3-노드(2개 키, 3개 링크)와 4-노드(3개 키, 4개 링크) 허용
루트가 4-노드일 때,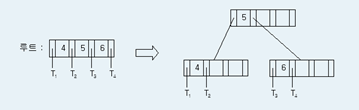 - 세 개의 2-노드로 변환 - 루트의 분할은 트리의 높이를 하나 증가 4-노드가 2-노드의 자식일 때,  - 중간 키를 부모로 보내 3-노드에 연결된 두 개의 2-노드로 변환 4-노드가 3-노드의 자식일 때,   - 4-노드에 연결된 두 개의 2-노드로 변환 - 즉, 중간 키를 부모로 보내고 2-노드로 변환 |
레드-블랙 트리(RB)
2-3-4트리를 표준 이진 트리로 표현한 방법
블랙 링크는 보통의 링크, 3-노드와 4-노드는 레드 링크로 연결된 이진트리

규칙
- 루트나 외부 노드는 모두 블랙
- 루트에서 외부 노드까지 경로 상에 2개의 연속된 레드 노드가 있으면 안됨!!
- 루트에서 각 외부 노드까지 경로에 있는 블랙 노드의 수는 모두 같음
- 동일한 키를 가지는 레코드는 노드의 왼쪽과 오른쪽에 모두 올 수 있음
- 동일 키가 여러 개 있을 때 주어진 키를 갖는 모든 노드를 찾는 것이 어려움
4-노드 분할 회전이 필요한 경우  |
단일 회전 이중 회전  |
삽입 과정   |
레드 블랙 트리의 삽입 시간 복잡도: O(logN), 탐색 시간 복잡도: O(logN)
AVL트리
높이 균형 이진 탐색 트리
오른쪽 서브트리와 왼쪽 서브 트리의 높이 차가 2이상이 되면 회전을 통해 트리의 높이 차를 1 이하로 유지

삽입 과정  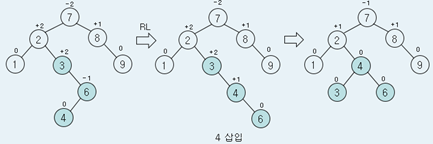  |
높이가 h인 이진 탐색 트리의 시간 복잡도는 O(h)이므로 O(N)이 됨
한쪽으로 치우친 편향 이진 트리가 되면 높이가 커지기 때문에 이를 방지하고자 높이의 균형을 이루는 AVL트리를 사용함
높이 차이를 1이하로 유지하는 AVL트리는 높이를 logh로 유지하므로 시간복잡도가 O(logN)이 됨
트라이(Trie)
문자열을 저장하고 효율적으로 탐색하기 위한 트리 형태의 자료구조
노드를 내부, 외부 노드로 나눠 내부 노드는 탐색시 왼쪽, 오른쪽 이동만을 나타내고 외부 노드는 키를 저장
키 비교는 외부 노드에서만 이루어져서 탐색당 1번 비교

사용 이유
- 탐색당 1번의 키 비교를 하기 때문에 빠름 → 검색어 자동완성, 찾기, 문자열 검사
단점
- 내부 노드는 기억 장소 낭비가 심함
- 내부, 외부 노드를 나눠 프로그래밍해야 하므로 구현이 어려움
B-트리
규칙
- 균형 트리로 노드에 2개 이상의 데이터(키)가 들어갈 수 있고, 항상 정렬된 상태
- 내부 노드는 M/2~M개의 자식을 가질 수 있음, 최대 M개의 자식을 가질 수 있는 B트리를 M차 B트리라고 함

- 특정 노드의 키가 K개면, 자식 노드의 개수는 K+1개여야 함 → 2개의 데이터를 가지면 자식 노드는 3개가 됨
- 특정 노드의 왼쪽 서브 트리는 특정 노드의 키보다 작은 값들로, 오른쪽 서브 트리는 큰 값

- 노드 내에 키는 floor(M/2) - 1개부터 최대 M-1개까지 포함 될 수 있음 → 3차 B트리는 노드 내에 0~2개의 데이터를 가 질 수 있음 (*floor는 내림 함수 --> ex.floor(3.7) = 3)
- 모든 리프 노드들이 같은 레벨에 존재해야 함. 즉, 루트에서 모든 리프까지 가는 경로의 길이가 같음

| B-트리 탐색 과정 루트에서 하향식으로 탐색 진행 찾고자 하는 값이 K일 때, 1. K와 노드의 키 값을 비교해 알맞은 자식 노드로 내려감 2. 리프 노드에 도달할 때까지 반복 3. 리프에서도 찾지 못하면 트리에 값이 존재하지 않음 |
| B-트리 삽입 과정 탐색과 다르게 상향식으로 진행. 항상 리프에서 시작 1. 트리가 비어 있다면 루트로 할당하고 K를 삽입 2. 비어있지 않다면, 데이터를 넣을 적절한 리프 노드를 탐색 3. 리프 노드에 데이터를 넣고 노드의 데이터 개수 허용 범위에 맞는지 판단하고 벗어나면 분리시킴 Case1. 분리가 일어나지 않는 경우 (노드의 데이터 개수 허용 범위 안에 들어옴)   Case2. 분리가 일어나는 경우   리프노드 [15, 16, 17]가 부적절한 상태  분리 진행, [14, 16, 18] 부적절 상태  분리 진행, 루트 노드 [10, 16, 21] 부적절  |
| B-트리 삭제 과정 Case1. 리프 노드에서 삭제 1-1] 리프노드에서 값을 삭제하더라도 최소 유지 개수 조건을 만족하는 경우  16을 삭제하고 아무 조치를 취하지 않음 1-2] 최소 유지 개수 조건을 만족하지 않지만 형제 노드에서 값을 빌려올 수 있는 경우  19를 제거하면 B트리 조건이 깨짐   부모 노드에서 17을 내리고 B트리 조건을 맞추기 위해 형제노드에서 16을 부모로 올림 1-3] 형제 노드에서 값을 빌려올 수 없지만, 부모 노드를 분할할 수 있을 경우  22를 제거하면 조건 깨짐  부모 노드를 분할시켜 조건 만족 1-4] 형제 노드에서 값을 빌려올 수 없지만, 부모 노드를 분할할 수 있을 경우 (Case2-2와 동일) Case2. 리프 노드가 아닌 내부 노드에서 삭제 2-1] 내부 노드에서 삭제할 때, 현재 노드 or 자식 노드의 최소 유지 개수의 최소보다 큰 경우  21을 삭제하면, 루트의 키는 1개인데 자식 노드가 3개라 조건이 깨짐  삭제 키의 LMax(19)나 RMin(22)와 값을 바꾸는 것으로 조건을 만족시킬 수 있음, LMax(19)를 올려주게 되면 [14, 17] 부분에서 B트리 조건이 깨지므로 위에서의 삭제 과정과 동일하게 해결함   따라서, 21을 삭제한 최종 트리 모습은  2-2] 현재 노드와 자식 노드 모두 키 개수가 최소인 경우 (@@@@@) --> 트리의 재구조화가 필요함  K(4)를 제거하면 조건 깨짐  K의 자식 노드를 합침  K의 부모인 10을 형제 노드에 합쳐줌. 그리고 10을 합친 K의 자식 노드와 연결해 줌 --> 하지만 루트와 [10,14,17] 부분이 조건이 깨짐, 분할이 필요 (삽입 과정에서 설명)  분할하면,  |
B-트리의 장단점
장점: 삽입/삭제 후에도 균형 트리 유지로 균등한 응답 속도 보장 (복잡도: O(logN))
단점: 삽입/삭제 시 트리의 균형을 유지하기 위해 복잡한 연산 수행이 필요(B 트리의 조건이 깨지지 않는 노드의 분할 연산)
- B-Tree : 데이터를 정렬해 탐색, 삽입, 삭제 및 순차 접근이 가능하도록 유지하는 트리형의 자료구조
- B+Tree : B Tree의 중위순회와 잦은 분배 및 합병에 따른 부하를 감소하기 위해 Index set과 Sequential set으로 구성한 트리
- Index set : 실제적인 키 값(Leaf node)을 찾아갈 수 있는 경로 제공이 목적
- Sequence set (순차) : Leaf Node값은 오름차순으로 정렬되어 있으며 삽입으로 인한 분기 시 Sequence set에 연결되면서, 순차성 유지
- B*Tree : B Tree의 문제점(보조 연산 필요)을 보완하기 위해서 B Tree를 약간 변형한 트리
B Tree에 비해 공간 활용도를 높일 수 있음 (B Tree는 최소 1/2면 분열할 수 있지만, B*Tree는 최소 2/3이 되어야 분열함)

'자료구조 & 알고리즘' 카테고리의 다른 글
| 정렬 알고리즘 (0) | 2022.12.19 |
|---|
